
Meta 為超過 1,100 種語言帶來語音轉文字、文字轉語音等功能
2023-05-24
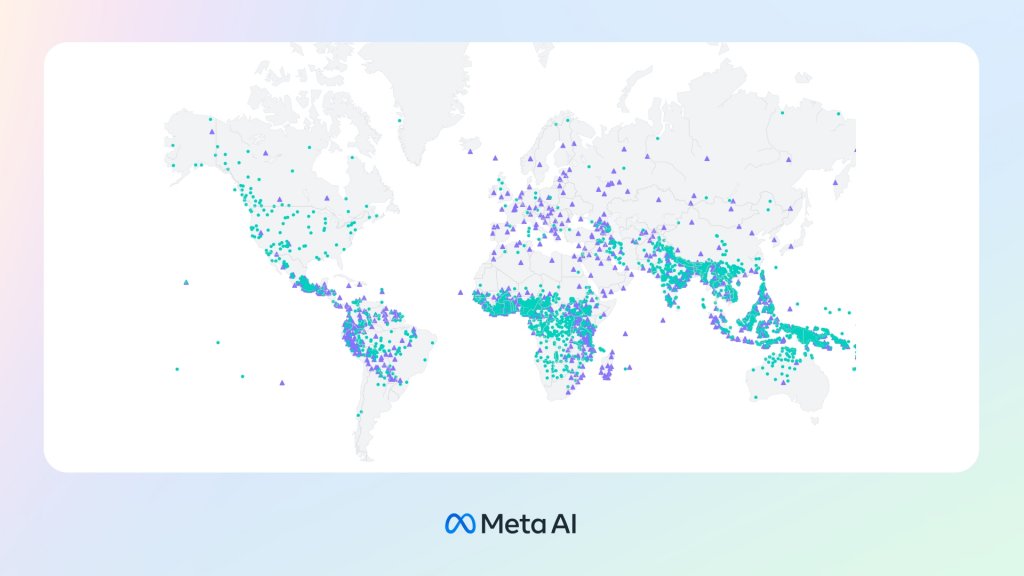
Meta 為超過 1,100 種語言帶來語音轉文字、文字轉語音等功能,配備理解並產生語音功能的機器,可以讓更多人存取各種資訊,
然而,
對於大多數語言來說,
在大規模多語言語音(Massively Multilingual Speech,MMS)項目中,
我們的研究結果顯示,
Meta 專注於多語言的廣泛層面上:在文字方面,NLLB 項目將多語言翻譯技術拓展至 200 種語言,而MMS項目則將語音技術擴展至更多語言。
+more